
I was previously involved in these projects (now finished, or which evolve in a new one):
Joint Energy-based Models for Generative EO Modelling
![]()
With Javiera Castillo-Navarro, Alex Boulch and Sebastien Lefevre we explored the potential of Energy-Based Models for generative modelling of Earth observation images. It leads to powerful applications such as image synthesis through Stochastic Gradient Langevin Dynamics, Out-Of-Distribution detection (see papers at ICLR/EBM ws and IGARSS in 2021), and Semi-Supervised Learning (see our TGRS paper).
[ EO-JEM preprint / EO-JEM in TGRS ]
Deep Interactive + Active Learning
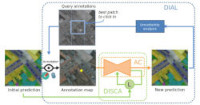
In Gaston Lenczner’s PhD, we design interactive deep neural networks to foster user/algorithm collaboration. In the context of semantic segmentation of remote sensing images, we target several use-cases including online correction of semantic maps (and model!) obtained by CNNs, domain adaptation to new locations (see our ISPRS’2020 and MACLEAN 2021), and transfer learning to add interactively new target classes to an existing model (see our IGARSS2022 paper). To this end, we combine acceleration tricks and active learning to make deep networks learn continuously and efficiently from user inputs. This work is a collaboration with Guy Le Besnerais, Adrien Chan-Hon-Tong (both from ONERA) and Nicola Luminari (Alteia)
[ DISIR @ ISPRS 2020 / DISIR code / DISCA @ ECMLPKDD/MacLean 2021 (Best student paper award!) / DISCA Code / DIAL arxiv / Transfer learning arxiv ]
Weakly-supervised Learning for Earth Observation
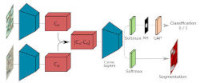
Large scale datasets created from crowdsourced labels or openly available data have become crucial to provide training data for large scale learning algorithms. While these datasets are easier to acquire, the data are frequently noisy and unreliable, which is motivating research on weakly supervised learning techniques. With Rodrigo Daudt, Alexandre Boulch and Yann Gousseau we propose the Guided Anisotropic Diffusion (GAD) algorithm, that we combine with Cycle-GANs and attention-based neural networks to overcome scarce and noisy labels, for application in post-natural disaster mapping and land-cover classification.
[ Mach. Learn. paper on Weakly-supervised learning for EO / CVPR’19/Earth Vision paper (Best student paper award!) / Rodrigo Daudt’s PhD thesis ]
Semi-Supervised Learning for Earth Observation
![]()
Labelled datasets are more and more common in EO, and yet this is only a waterdrop in the ocean of unlabelled imagery. In Javiera Castillo-Navarro’s PhD, co-supervised with A. Boulch and S. Lefèvre, we explore semi-supervised strategies to harness unlabelled data for better semantic segmentation. In particular, we showed that common datasets were not suitable to assess real-life generalization issues (paper), released MiniFrance the 1st large-scale dataset designed for semi-supervised training and evaluation, and proposed semi-supervised neural nets (paper) with self-supervised losses (paper).
[ Mach. Learn. paper on Semi-supervised learning for EO / MiniFrance dataset ]
Semantic Change Detection
![]()
With the very high resolution now available even from space, local changes can now be characterized precisely. Rodrigo Daudt, Alexandre Boulch, Yann Gousseau and I have proposed the first deep neural network architectures for change detection in Earth-observation. We also created and released OSCD, a dataset with reference data for training such nets. The last evolution of this line of work is Semantic Change Detection, which allows to characterize the modification of land use, and we propose a Multi-Task Learning network to solve this problem automatically along with the high-res HRSCD dataset.
[ ICIP paper on siamese nets for change detection / code / OSCD dataset / HRSCD dataset / arxiv ]
AerialMTL: Multi-Task Learning for Height and Semantics prediction from bird’s view
![]()
Thanks to statistical modelling, it is now possible to build elevation or height models from a single aerial image, without the need for stereo! With Marcela Carvalho we proposed to leverage multi-task learning to build stronger representations, by learning classes of interest along with the relative height. Indeed, similar classes of urban objects are likely to have similar heights, which brings consistence to the model. We published our results in a paper in GRSL and published the AerialMTL code.
[ paper in Geosci. Rem. Sens. Lett. / preprint / AerialMTL github Code description ]
Deep Learning for Hyperspectral data: DeepHyperX and HyperGANs
![]()
Hyperspectral sensors offer a unique perception on the world, in which spectral information (at multiple wavelengths, or so-to-say “colors”) is as important as the spatial one. With Nicolas Audebert (prime) and Sebastien Lefevre, we investigated and reviewd various types of neural network architectures, from 1D to 3D, through complex combinations of spatial-spectral ones, to process hyperspectral data for classification. It resulted in a review in GRSM and the associated DeepHyperX toolbox with many models ready to use on most common benchmarks! We also explored the use of Generative Adversarial Networks (GANs) to (conditionally) synthetize pure spectra (or endmmbers), and also published this IGARSS paper and the HyperGANs toolbox: GANs for hyperspectral.
[ Deep Learning for Hyperspectral Classification / DeepHyperX toolbox / GANs for hyperspectral paper / HyperGANs toolbox ]
D^3 Net: Depth Estimation from a Single Image with Deep Depth from Defocus
![]()
Turning 2D images into depth is now possible with a monocular camera, without neither stereo nor active sensor. With Marcela Carvalho and Pauline Trouvé, we designed a dense network for depth estimation from a single image. We investigate how to model the right loss for such a network, and how blur from defocus can help us predict better estimates. This network ranks among the top ones of the state of the art on the NUYv2 dataset while being simpler to train in a single phase than most competitors.
[ ICIP’18 paper / ECCV/W’18 paper / video / code ]
Joint Use of EO Data and Cartography
![]()
Cartography and especially crowd-sourced geographic information like OpenStreetMap is a great way to drive a neural network towards a correct classification. With Nicolas Audebert and Sébastien Lefèvre, we built fusion networks able handle efficiently this new input.
The SpaceNet Challenge round 2 winner is using a similar solution: see his blog post which mentions our paper. OSM as input is promising !
[ CVPR’17/EarthVision paper / arxiv ]
SnapNet: 3D Semantic Labeling
![]()
As 3D sensors become ubiquitous, recognizing stuff and things in 3D data is essential. So, we developed SnapNet, a multi-view conv net for semantic labeling of unstructured 3D point clouds. During more than one year, it led the semantic3D leaderboard for 3D urban mapping, and still is among the top ones. The paper was presented at EuroGraphics/3DOR 2017 and has now been published in Computer and Graphics. The code is also available for playing with your own data.
Object Detection in Remote Sensing
![]()
With the accuracy of deep conv nets for pixelwise labeling, it is now possible to build powerful object detectors for aerial imagery. We proposed an approach to detect and segment vehicles, and then recognize their type. Our work was awarded the award for the best contribution to the ISPRS 2D semantic labeling benchmark at GeoBIA’16.
[ Segment-before-detect paper]
SnapNet-R: Object Recognition for Robotics
![]()
In the context of robotic exploration (using micro-drones or ground robots), we aim at developing efficient object detectors and trackers that are able to adapt to a new environment. We explore how multimodal RGB-D data offers reliable and complementary ways of sensing in challenging conditions. Joris Guerry has developped multimodal networks that gets high detection rates for people detection and released the ONERA.ROOM dataset. We also proposed the SnapNet-R multi-view network for 3D-consistent data augmentation: it gets top state-of-the-art results on NYUv2 and Sun RGB-D datasets for robotic semantic labeling.
[ ONERA.ROOM / video / ECMR paper about people detection / ICCV/3DRMS paper about robotic semantic labeling with SnapNet-R ]
Search-and-Rescue with 3D captured from UAVs
![]()
We are designing classifiers for 3D data captured using Lidar sensors or photogrammetry. In the FP7 Inachus Project, we build tools for urban Search and Rescue after natural or industrial disasters: semantic maps (including safe roads and risk maps) or analysis of building damages (as shown in the image on the left: intact/blue to debris/purple). They are based on SnapNet, our multi-view convolutional net for 3D point-cloud semantic labeling.
UAV Object Detection and Recognition
![]()
With Martial Sanfourche, we designed detectors of object of interest in images obtained from airborne sensors (UAV and planes), using a mix of geometric-template matching and learning-based classifiers. A typical use-case is a Search-and-Rescue mission in an urban environment, which objectives like cartography, obstacle avoidance or people and vehicle detection [video]. This research was carried on in the FP7 Darius and Azur projects.
We presented our work on UAV-based 3D modelling and event localization [video] at the 2nd field trial of the FP7 Darius project which simulated an Urban (Earthquake) SaR Demonstration.
[ IROS’13 paper / video #1 / video #2 ]
Car Detection in Aerial Images
![]()
With Hicham Randrianarivo and Marin Ferecatu, we built powerful and fast detectors able to retrieve cars in aerial images. Our Discriminatively-trained model mixture (DtMM) was able to encode the various orientations and appearances of the cars for retrieval in higly-complex urban environments. It relied on a HOG encoding for description and a hard-negative search ofr training of linear classifiers
Interactive Learning
![]()
Over the years, I worked on developping various methods for interactive and user-friendly design of classifiers and detectors, typically non-parametric methods like boosting and support-vector machines. The main application we investigated in the DGA-funded project Efusion was online learning of patterns of interest (objects or changes) in aerial and satellite images.
[See ICPR’2014 paper for a synthesis ].
Deformable Part Models in Remote Sensing
![]()
With Hicham Randrianarivo, we adapted Felzenswalb’s infamous Deformable Part Models to object detection in aerial images. First we shown they could be used for man-made structures in difficult urban environments [cf. paper at IGARSS 2013] and then pushed them for fusion of multi-resolution, multimodal optical and hyperspectral imagery [cf. paper at IGARSS’14].
Tomography
![]()
I was once interested in 3D reconstruction in tomographic imaging. The new confocal microscope we worked with was deplyed at Institut Pasteur in Spencer Shorte’s team and made possible the observation of non-adherent living cells. We used bayesian inference, data fusion and deconvolution to produce 3D volumic images of these living cells. This work was achieved in the FP6 Automation project, with Bernard Chalmond, Jiaping Wang and Alain Trouvé from the Applied Mathematics Lab of the ENS Cachan.
[ Paper / 2005 CNISF/L’usine nouvelle Science Award ]
Image Content Recognition
![]()
My postdoctoral project was carried out at the University of Bern with Horst Bunke and the CNR di Pisa with Giuseppe Amato, as a member of the ERCIM fellowship program. I have designed predictors that can learn how to recognize scenes, like particular landscapes, sport pictures, images with people. Techniques include feature selection, kernel methods, graph matching and bayesian combination of classifiers. This was used to generate automatic annotation of multimedia documents and improve search facilities in digital libraries.
[A popularization article in ERCIM news]
Image and Video Indexing
![]()
I did my PhD at INRIA/Imedia research group, which is interested on content-based image retrieval. I worked on techniques of supervised and unsupervised classification to find and manage categories of visually similar images. I have developed an original algorithm for clustering : ARC (Adaptive Robust Competition).
[ ICPR’02 paper / web version ]
For years since the time of my PhD and my then perl-generated pure html homepage, I used to include a link to these nice kittens who play music on the beach. Years after, this link is still up. Internet is awesome. Enjoy.